
Komplexe Begriffe lassen sich über Vergleiche und Ordnungsrelationen berechnen.
Zahlen sind sehr präzise. Wir wissen genau, was Menschen kaufen, welche Filme sie sehen, welche Bücher sie kaufen, welche Webseiten sie aufrufen und wieviel Zeit sie dort verbringen.
Welche Bücher sie lesen, warum sie Dinge kaufen und ob sie eine Webseite aus Neugierde oder aus Langeweile anklicken, darüber wissen wir weniger. Gerade bei Webseiten können wir einen Wert aus Scrolltiefe und Verweildauer berechnen, der erahnen lässt, ob die Seite gelesen oder schnell wieder geschlossen wurde, Aktivitätsmessungen können Hinweise darauf geben, ob eine Leserin vor einer Seite eingeschlafen ist, vergessen hat, den Browsertab zu schließen, oder sich mit den Inhalten auseinandergesetzt hat.
Die Interpretation dieser Werte ist deutlich weniger präzise als es die Zahlen, in denen sie sich ausdrücken lassen vermuten ließen.
Ich arbeite mit Kombinationen von mehreren Werten, je nachdem, welche Details verfügbar sind.
Die erste Entscheidung dabei: Welche Art von Daten soll das Ergebnis sein? Daten können kategorisieren (also in Schubladen ordnen), Reihenfolgen und Grössenverhältnisse feststellen, Filtern und Schwellwerte bilden, und ordnen und Relationen darstellen.
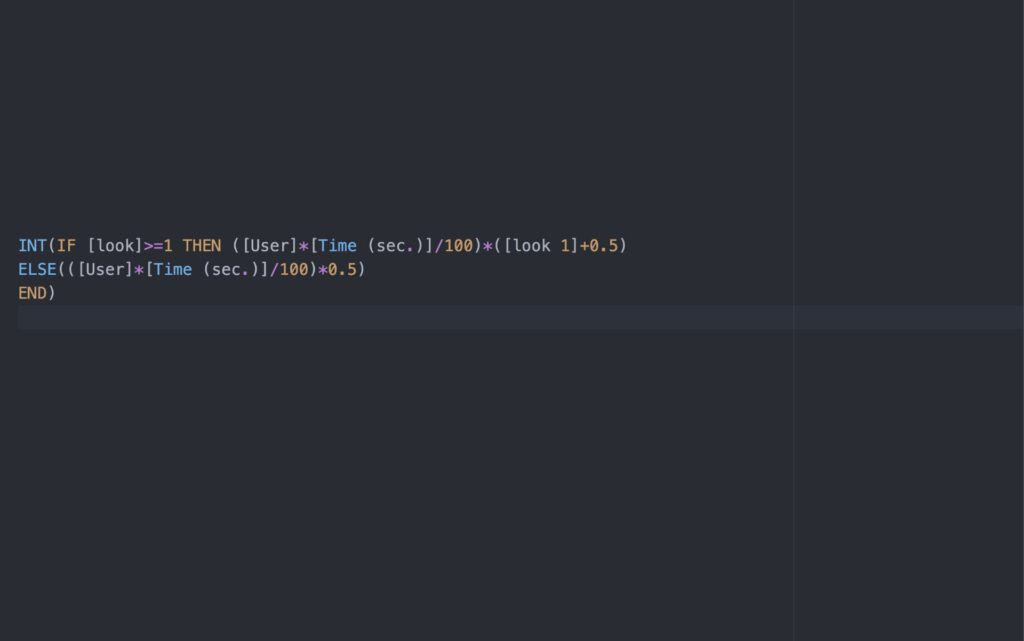
Vage Werte wie Interesse können meines Erachtens am ehesten als Ordnungsrelationen abgebildet werden: X ist für Z interessanter als Y. Dabei kann X noch immer recht uninteressant sein, aber der Unterschied eröffnet die Möglichkeit, Entscheidungen zu treffen. Ordnungsrelationen machen vor allem dann Sinn, wenn sie in mehreren Dimensionen ordnen. Dann sind konkreter Aussagen möglich. X ist für Z interessanter als Y, wobei Z sich von A unterscheidet – die Trennung von Messwerten (der Interessegrad von X und Y) und Dimensionen (Z und A, etwa unterschiedliche Zielgruppen oder Segmente) bietet noch mehr Information, ohne vage Begriffe wie Interesse in absoluten Kriterien erfassen zu müssen. X ist für Z zum Zeitpunkt t interessanter als Y ist eine andere Möglichkeit, Messwerte und Dimensionen zu präzisieren, indem konkrete Aussagen an eine Zeitdimension geknüpft werden.
Reine Häufigkeiten eignen sich wenig für solche Ordnungsrelationen. Ein erster schneller Klick kann auf vieles zurückzuführen sein, das muss nicht zwingend Interessen abbilden. Auch hier sind zusätzliche weitere Kriterien notwendig, um vom Vorhandensein einer Interaktion auf deren Relevanz schließen zu können. Das kann zum Beispiel die Dauer der Interaktion sein, es kann aber auch die Häufigkeit (oder Dauer) der Interaktion in Relation zu Häufigkeit und Dauer anderer Interaktionen oder der gleichen Interaktion in anderen Segmenten und Zielgruppen oder der gleichen Interaktion zu unterschiedlichen Zeitpunkten sein.
Aus solchen mehrdimensionalen Relationen entsteht Information.
Was bedeutet das ganz praktisch? Aus einfachen Messwerken kann nur schwer Information entstehen. Bessere Datenqualität braucht mehr Messpunkte, die anhand gezielter Fragestellungen gesetzt werden müssen. Dann kann mit konkreten Rechnungen begonnen werden. Und Daten werden nie absolute Antworten geben. Innerhalb eines spezifischen und konkreten Rahmen kann aus Daten Information werden, die in der Anwendung auf konkrete Fragen Bedeutung erlangen kann.
Damit gewinnt man eine Entscheidungsgrundlage (wenn es eine konkrete Frage gibt, die entschieden werden kann). Über den Kern des gesuchten Begriffs – in diesem Fall Interesse – sagt das aber nichts aus.






 Ich bin Journalist, Wissenschafts- und Technologiehistoriker,
Ich bin Journalist, Wissenschafts- und Technologiehistoriker,